Lumina-Image_2.0
0
0
0
0
Portrait PhotographyGirl
2.0
최근 업데이트: 첫 번 게시:
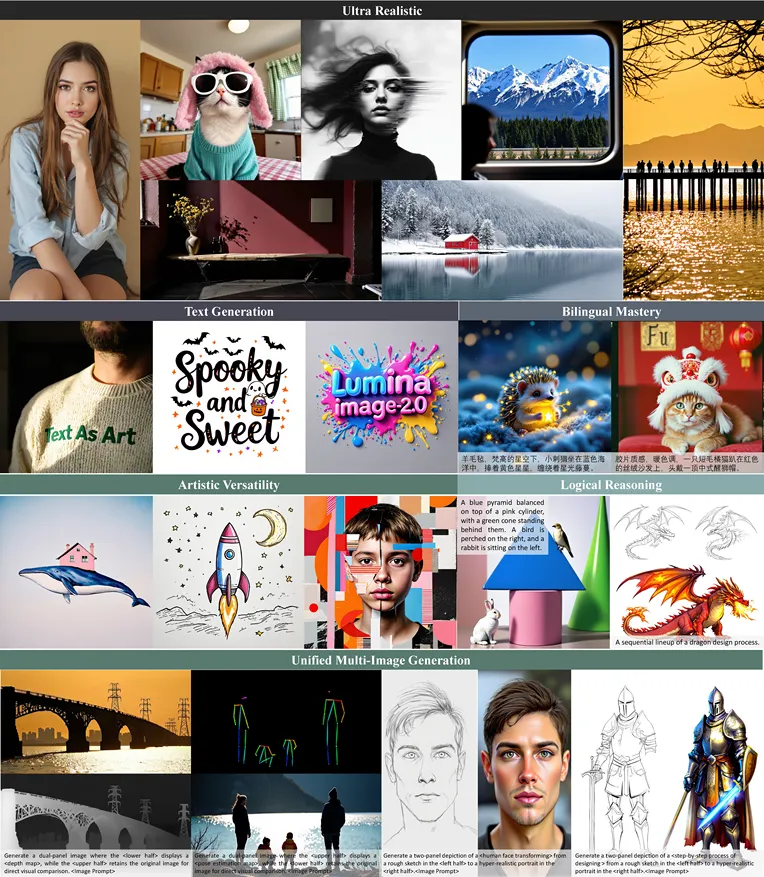
 Image info
Image info Image info
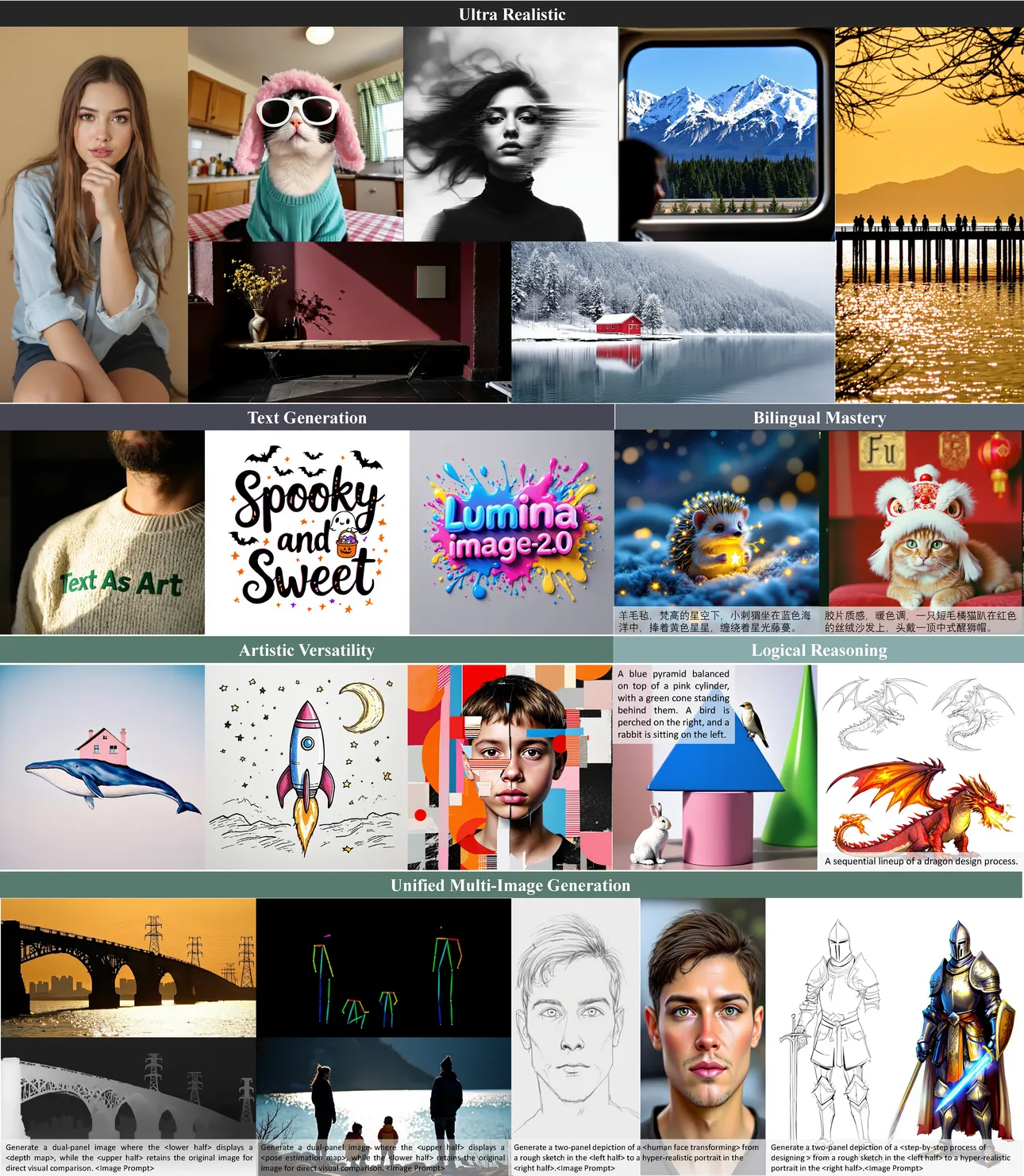
Image infoLumina-Image-2.0 是上海 AI 智能实验室推出的开源统一图像生成模型
技术架构
Transformer 架构:以 Transformer 为核心架构,能处理长距离依赖关系,采用 Gemma-2-2B 作为文本编码器,可高效地将文本提示转化为图像生成所需的特征。
扩散模型:使用基于流的扩散模型,通过逐步去除噪声来生成图像,即先给图像数据添加高斯噪声,再训练神经网络逐步去噪以恢复清晰图像。
VAE:采用 FLUX-VAE-16CH 作为变分自编码器,用于高效地编码和解码图像。
模型参数:参数量为 26 亿,相对较小的参数量使其在资源效率方面表现出色,能在保持高质量生成的同时,降低计算资源的消耗。
核心功能
高质量图像生成:可生成写真、艺术字、风格化图像、逻辑推理图像等多种高质量图像。
多语言支持:支持中英双语提示词,能根据不同语言的描述生成对应的图像。
复杂提示词理解:对动物、人物表情等复杂提示词的理解和展示能力较强,能更准确地根据文本描述生成图像。
多种推理求解器支持:支持中点求解器、欧拉求解器和 DPM 求解器等多种推理求解器,可根据不同的生成需求和资源限制进行选择,在速度和质量间取得平衡。
与 ComfyUI 集成:已实现对 ComfyUI 的原生支持,用户可通过 ComfyUI 直接使用该模型。
性能表现
提示词理解准确:在文本对齐能力上达到行业领先水平,对提示词的理解准确性较高,在艺术性以及风格表现方面也较为出色。
出图速度快:相比普通 FLUX 模型,出图速度有明显提升。
토론
가장 인기
|
최신
보내기
곧 오픈
다운로드
(0.00KB)
자세히
유형
온라인 생성 횟수
0
다운로드
0
추천 매개변수
Sampler method
CFG
4
VAE
없음
갤러리
가장 인기
|
최신