ACE Plus FFT | ace_plus_fft
v1
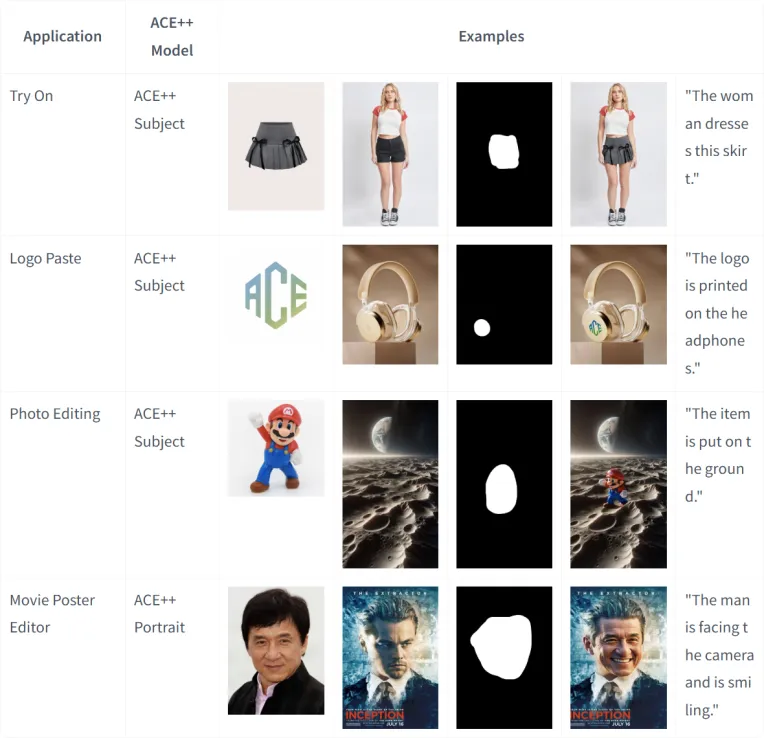
 Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image infoace_plus_fft.safetensors
https://ali-vilab.github.io/ACE_plus_page
📚 Introduction
The original intention behind the design of ACE++ was to unify reference image generation, local editing, and controllable generation into a single framework, and to enable one model to adapt to a wider range of tasks. A more versatile model is often capable of handling more complex tasks. We have already released three LoRA models, focusing on portraits, objects, and regional editing, with the expectation that each would demonstrate strong adaptability within their respective domains. Undoubtedly, this presents certain challenges.
We are currently training a fully fine-tuned model, which has now entered the final stage of quality tuning. We are confident it will be released soon. This model will support a broader range of capabilities and is expected to empower community developers to build even more interesting applications.
📢 News
- [2025.01.06] Release the code and models of ACE++.
- [2025.01.07] Release the demo on HuggingFace.
- [2025.01.16] Release the training code for lora.
- [2025.02.15] Collection of workflows in Comfyui.
- [2025.02.15] Release the config for fully fine-tuning.
- [2025.03.03] Release a unified fft model for ACE++, support more image to image tasks.
🔥The unified fft model for ACE++
Fully finetuning a composite model with ACE’s data to support various editing and reference generation tasks through an instructive approach.
We found that there are conflicts between the repainting task and the editing task during the experimental process. This is because the edited image is concatenated with noise in the channel dimension, whereas the repainting task modifies the region using zero pixel values in the VAE's latent space. The editing task uses RGB pixel values in the modified region through the VAE's latent space, which is similar to the distribution of the non-modified part of the repainting task, making it a challenge for the model to distinguish between the two tasks.
To address this issue, we introduced 64 additional channels in the channel dimension to differentiate between these two tasks. In these channels, we place the latent representation of the pixel space from the edited image, while keeping other channels consistent with the repainting task. This approach significantly enhances the model's adaptability to different tasks.
One issue with this approach is that it changes the input channel number of the FLUX-Fill-Dev model from 384 to 448. The specific configuration can be referenced in the configuration file.
Comfyui Workflows in community
We are deeply grateful to the community developers for building many fascinating applications based on the ACE++ series of models. During this process, we have received valuable feedback, particularly regarding artifacts in generated images and the stability of the results. In response to these issues, many developers have proposed creative solutions, which have greatly inspired us, and we pay tribute to them. At the same time, we will take these concerns into account in our further optimization efforts, carefully evaluating and testing before releasing new models.
In the table below, we have briefly listed some workflows for everyone to use.